在科技界的风云变幻中,一场源自东方的风暴正悄然席卷全球,令硅谷巨头与华尔街大鳄纷纷侧目。这股力量的核心,是一个名为DeepSeek(深度求索)的人工智能公司,其凭借一款名为DeepSeek-R1的大语言模型,短时间内便在全球范围内引发了轰动。
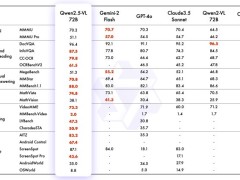
DeepSeek,这家由中国对冲基金幻方量化于2023年5月在杭州创立的AI新秀,近日以其卓越的技术实力震撼了全球科技圈。其发布的DeepSeek-R1模型,不仅在推理能力上与OpenAI的顶尖模型o1并驾齐驱,甚至在某些方面更胜一筹。这款模型能够运用“思维链”方式逐步推理,迅速解答复杂问题,且训练成本仅为OpenAI的3%-5%,使用的GPU芯片数量也大幅减少。

更令人瞩目的是,DeepSeek-R1采用了完全开源的策略,使得全球开发者能够自由地对模型进行微调和训练,极大地降低了使用门槛。与之相比,OpenAI的o1模型则向用户收取高额费用,且对服务器的依赖较重。DeepSeek-R1的出现,无疑为全球用户提供了一个更为便捷、高效且经济的选择。
DeepSeek-R1的成功,不仅在于其卓越的性能和低廉的成本,更在于其背后所代表的创新理念。DeepSeek团队没有盲目追求算力上的极致,而是选择了优化算法,通过强化学习技术进行“后训练”,减少对大规模人工标注数据集的依赖,从而降低了数据收集和标注的成本。同时,R1模型通过学习思维链的方式逐步推理,极大地提升了推理能力,使得模型在解决复杂问题时能够更有效地利用计算资源。
这一创新理念,不仅让DeepSeek-R1在技术上取得了突破,更在商业上取得了巨大成功。随着DeepSeek-R1的火爆,华尔街的科技股估值逻辑也悄然发生了变化。此前,由于AI的发展和演变离不开最尖端AI芯片的支持,英伟达等芯片巨头成为了华尔街的宠儿。然而,DeepSeek-R1的成功却颠覆了这一逻辑,证明了即使在不依赖高端芯片的情况下,也能打造出顶尖的大模型。
这一变化,直接导致了英伟达等芯片巨头的股价大幅下跌。英伟达在R1发布后的首个交易日股价下探16.97%,市值蒸发近6000亿美元。与此同时,台积电、阿斯麦等半导体产业链上的企业也未能幸免,股价纷纷下挫。这一场风暴,无疑给全球科技股市场带来了巨大的冲击。
然而,DeepSeek的征程并未止步。在发布DeepSeek-R1后不久,DeepSeek又推出了开源多模态AI模型Janus-Pro,这款模型能够同时处理文本和图像,且在图像生成基准测试中超越了OpenAI的DALL-E 3模型。这一系列的创新成果,不仅展示了DeepSeek强大的技术实力,更让全球科技界看到了中国AI企业的崛起。
值得注意的是,尽管DeepSeek在全球范围内引发了轰动,但其也面临着来自各方的挑战和攻击。不过,DeepSeek团队并未因此退缩,而是选择了以更强的实力来回应。他们坚信,只有不断创新、不断进步,才能在激烈的市场竞争中立于不败之地。
随着农历新年的临近,中国人都沉浸在节日的喜庆氛围中。对于DeepSeek团队来说,这既是一个难得的休息机会,也是一个新的开始。他们期待着在未来的日子里,能够继续用创新的技术和卓越的产品,为全球用户带来更多的惊喜和改变。