在人工智能领域,一场关于资源与策略的竞争正在悄然上演。知名投资人朱啸虎指出,大型科技公司正陷入参数升级的“军备竞赛”,而初创企业则寻求在大厂忽视的细分市场中寻找突破。医疗行业,以其高风险性和对精准性的极高要求,成为数字化进程中的一块难啃的骨头。然而,这并未阻止AI企业在这一领域深耕细作,特别是在垂直行业大模型上的投入。
医疗行业对AI的需求远非通用模型所能满足。方舟健客技术高级副总裁郭陟比喻道,通用大模型如同初出茅庐的医学生,虽具备广泛的基础知识,但缺乏实战经验。要成为某一领域的专家,如妇科专家,需要长时间的临床实践、科研学习和经验积累。医疗AI的发展路径亦是如此,从通用大模型向垂直大模型的进化,是提升服务质量和专业性的关键。
壹生检康,一家专注于女性健康检测的公司,深刻体会到了这一转变的必要性。在女性健康领域深耕三年后,他们发现通用大模型在解决实际问题时存在诸多不足,如回答不够准确、特定场景下的自由发挥难以控制等。开源DeepSeek的出现,为行业带来了对大模型更深层次的理解,也为垂直大模型的低成本实现提供了可能。在此背景下,壹生检康决定自研妇科垂直大模型。
在选择基础模型时,团队综合考虑了技术资源和模型性能,最终选定了32B参数量的QwQ_32B模型。这一选择基于其良好的医学知识预训练基础、适中的参数规模以及满足实时诊断咨询需求的推理速度。该模型具备输出推理过程的能力,符合临床诊断对可解释性的高要求。
数据准备与训练策略方面,团队利用旗下toC应用“闺蜜医生”平台积累的真实病例数据,通过DeepSeek蒸馏出诊断过程、结果和建议,用于第一轮训练。然而,未经标注的蒸馏数据对模型能力提升有限。第二轮训练采用了医生团队逐条审核标注的数据,显著提升了模型诊断准确率。针对数据失衡问题,团队通过规则合成补充了更多数据,构建起覆盖全症状、均衡化的数据集。
为了高效评估模型性能,团队设计了自动化评估裁判模型,能够快速对比训练前后的准确率变化。同时,还邀请了多位三甲医院的妇科医生对模型输出进行人工评估,确保评估结果的公正性和客观性。
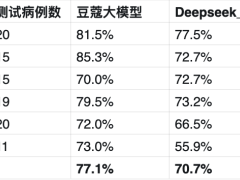
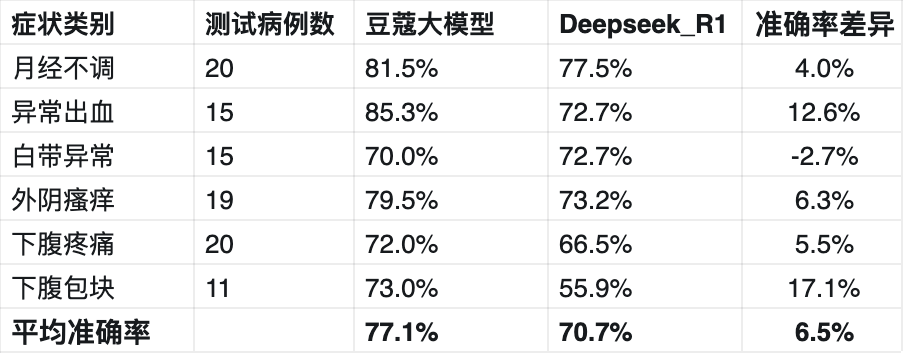
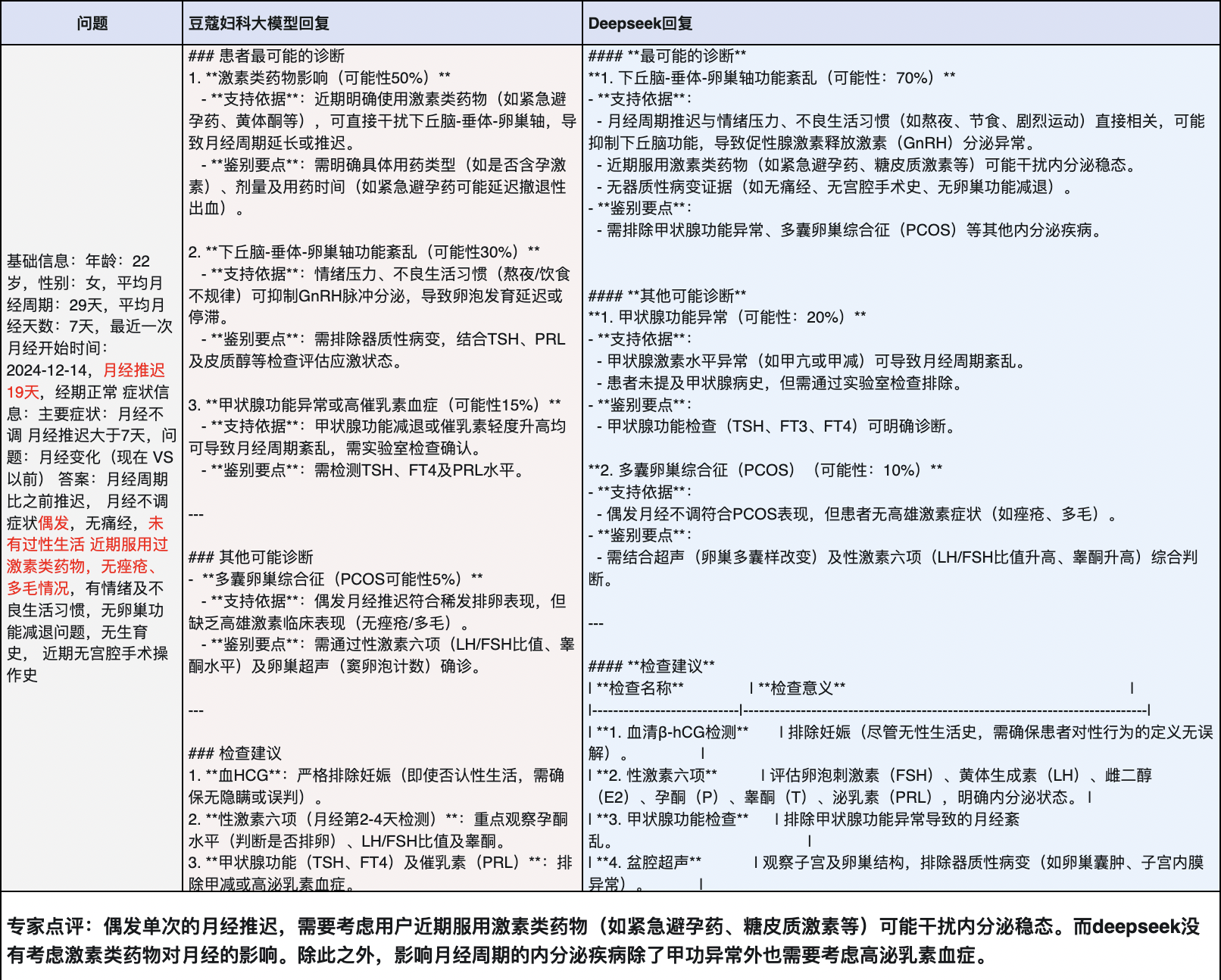
经过多轮训练和评估,豆蔻妇科大模型在月经不调、异常出血、白带异常等六大症状上的诊断准确率达到了77.1%,高出DeepSeek 7%。在特定疾病的诊断上,如月经推迟,豆蔻模型能够考虑更多因素,如用户近期服用的药物对内分泌的影响,展现出更高的专业度和性能。
豆蔻妇科大模型的应用场景广泛,既可用于服务C端用户,提供私密、专业、精准的健康咨询建议,也可用于赋能B端机构,如基层诊所和大健康机构,缓解专业妇科医生资源匮乏的问题。通过简单的自有知识库+RAG训练,这些机构可以快速上线自己的妇科AI医生,提升服务质量。
在模型部署方面,团队对训练后的模型进行了量化处理,以降低推理成本。经过测试,最终选择了INT8量化版本,在保证准确率的同时,实现了在较少资源上的高效运行。
豆蔻妇科大模型的成功研发,不仅提升了医疗服务的专业性和精准度,也为AI在医疗行业的应用提供了新的思路和方向。随着技术的不断进步和应用场景的拓展,AI将在医疗领域发挥越来越重要的作用。