近日,阿里巴巴旗下的通义千问团队宣布了一项重大进展,正式推出了其旗舰级的视觉语言模型Qwen2.5-VL。此次开源的版本涵盖了3B、7B以及72B三种不同规模,以满足多样化的应用需求。
Qwen2.5-VL作为Qwen模型家族的新成员,展现了强大的视觉理解能力。它不仅能够准确识别诸如花鸟鱼虫等常见物体,更能够深入解析图像中的文本、图表、图标、图形以及整体布局,为用户带来更为详尽的信息解读。
尤为Qwen2.5-VL还具备作为视觉代理的能力。它能够像人一样,通过推理动态地使用各种工具,甚至初步掌握了操作电脑和手机的技能,为智能化应用开辟了全新的可能性。
在视频处理方面,Qwen2.5-VL同样表现出色。它能够轻松理解超过一小时的长视频内容,并凭借精准定位相关视频片段的能力,有效捕捉事件的关键信息,为用户节省了大量查找时间。
Qwen2.5-VL还具备强大的视觉定位功能。它能够通过生成边界框或点来精确定位图像中的物体,并以稳定的JSON格式输出坐标和属性信息,为图像分析提供了有力的支持。
对于结构化数据的处理,Qwen2.5-VL同样游刃有余。无论是发票、表单还是表格等数据,它都能够实现内容的结构化输出,极大地提升了金融、商业等领域的工作效率。
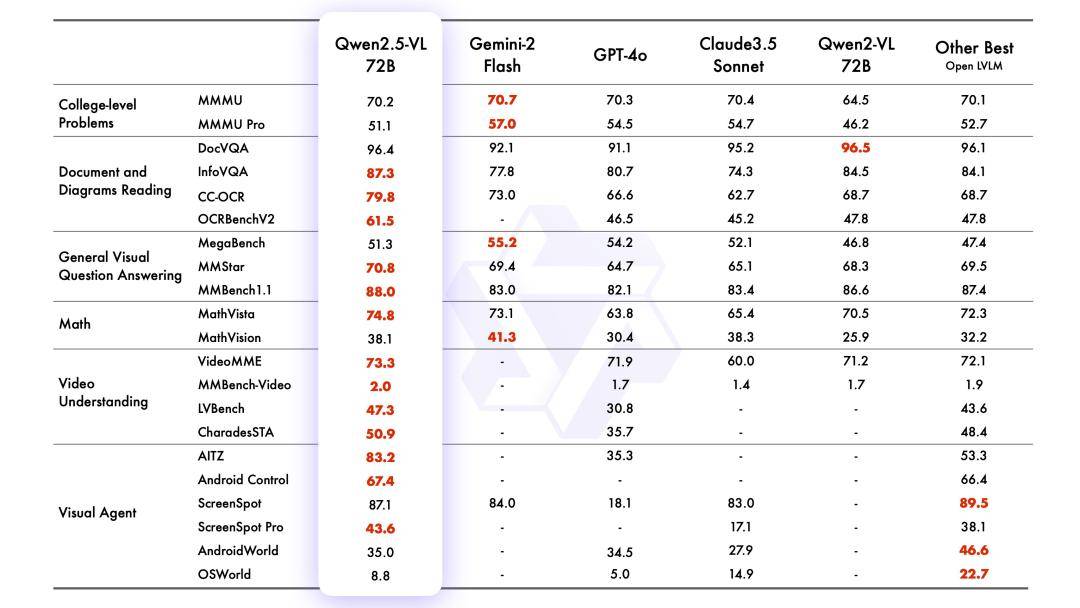
在官方公布的测试中,旗舰模型Qwen2.5-VL-72B-Instruct在一系列涵盖多个领域和任务的基准测试中均取得了优异成绩。特别是在理解文档和图表方面,它展现出了显著的优势。同时,作为视觉代理进行操作时,也无需进行特定任务的微调,展现了极高的灵活性和适用性。
在较小模型方面,Qwen2.5-VL同样表现出色。7B版本的模型在多个任务中超越了GPT-4o-mini,而3B版本则作为端侧AI的潜力股,性能超越了前代7B模型,为用户提供了更为高效、便捷的智能化体验。
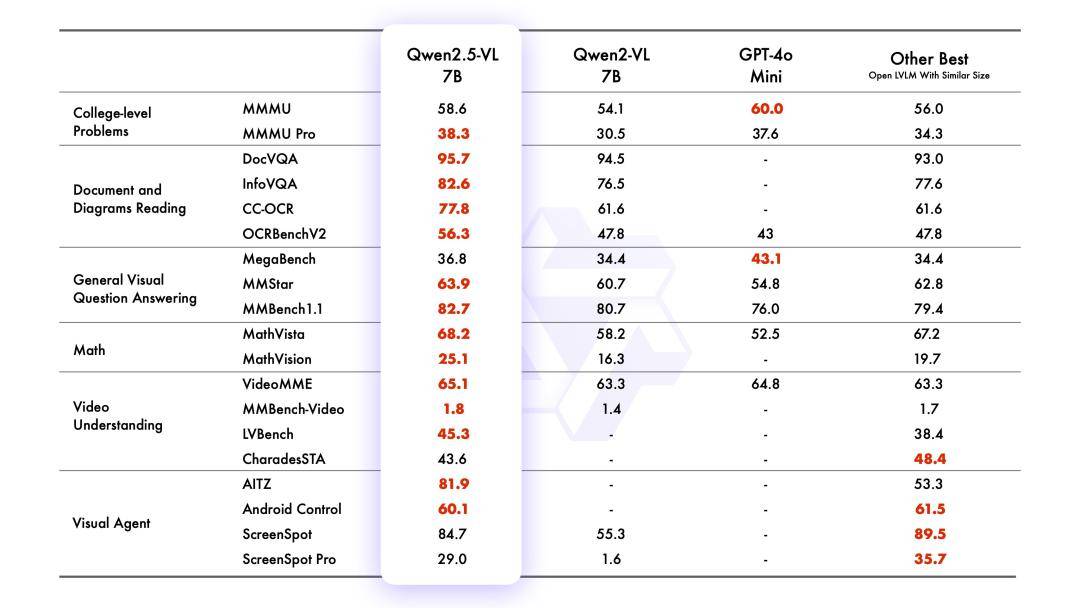
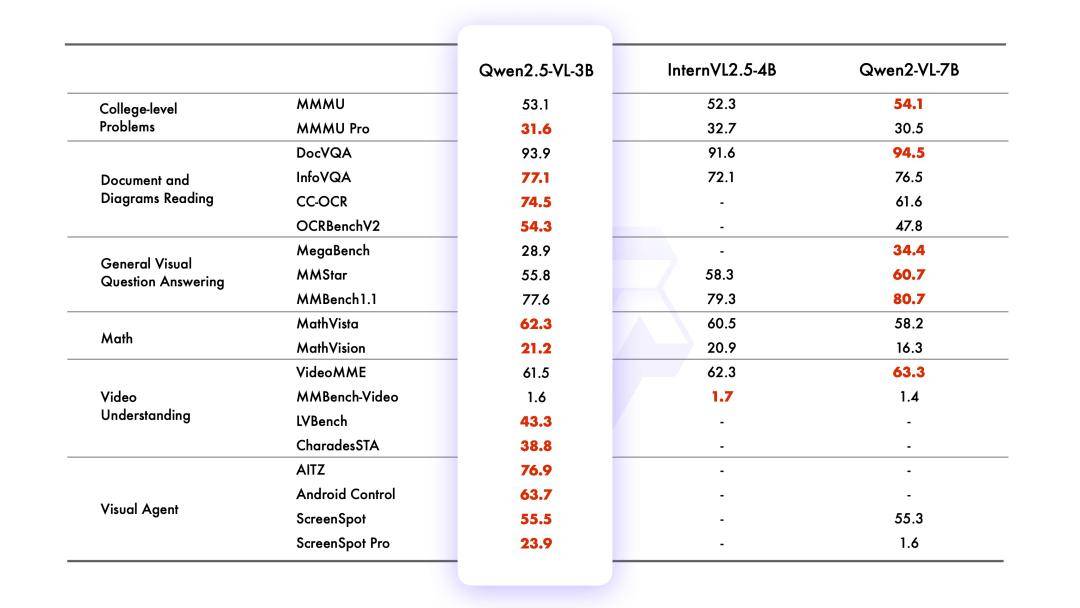
据通义千问团队介绍,与Qwen2-VL相比,Qwen2.5-VL在模型结构和感知能力上均进行了优化升级。它增强了对时间和空间尺度的感知能力,并简化了网络结构以提高模型效率。这些改进使得Qwen2.5-VL在智能化应用中更加智能、高效。


















