文 | 追问nextquestion
机器的学习能力,对我们来说已是习以为常,甚至有些人会觉得,“只要数据足够,机器什么都能学”。但通常我们谈论的学习,都是建立在“基于外部观察”的框架之下。除了常见的阅读、听课等典型学习场景,还有一种在我们内心深处(思维内部)进行的学习,这就是所谓的“通过思考学习(learning by thinking, LbT)”。
想想看,这种现象在日常生活中无处不在:科学家通过思考实验获得新见解、司机通过心智模拟发现如何绕开障碍,或者作家在尝试表达自己的想法时学到新知识……这些例子中的学习,都是在没有新的外界输入的情况下发生的。随着计算机科学的发展,LbT现象变得更加明显。
例如,GPT-4在解释过程中纠正了一个误解,并由此得出正确的结论,整个过程中未受任何外界反馈影响。当大型语言模型(LLMs)被要求“逐步思考”或模拟思维链(Chain-of-Thought)时[1],同样可以在没有外部纠正的情况下提供更准确的答案。
▷GPT-4对话截图。图源:GPT
但LbT常被认为是一种“悖论”。这一方面是因为,从某种意义上说,学习者并没有获得新的信息——他们所能利用的,只是已存在于脑海中的元素;而另一方面,学习又确实发生了——学习者获得了新的知识(比如数学问题的答案)或新的能力(比如回答新问题的能力或进行新推理的能力)。
近日,普林斯顿大学心理系概念与认知实验室的Tania Lombrozo教授在Trends in Cognitive Sciences上发表了一篇综述,为这一悖论提出了解决方法[2]。通过对解释、模拟、比较和推理这四类具体的学习方式的分析,这篇文章揭示了它们背后人类和人工智能之间相似的计算问题和解决方案——二者都是在利用重新表征现有信息,来支持更可靠的推理。最后她指出,作为人类这样一种资源有限的系统,LbT帮助我们按照当下需求提取必要的信息并进行处理,而不必时刻产生新的信息。
那么,这种近乎“空想”的学习行为所产生的结果,能否被视作“真理”呢?在下定结论前,让我们先回顾一下支持LbT的证据。
▷Lombrozo, Tania. "Learning by thinking in natural and artificial minds." Trends in Cognitive Sciences (2024).
01 四种典型的LbT学习方式
我们先从LbT的四个实例来进行探讨,即通过解释、模拟、类比和推理进行学习。当然,LbT并不仅限于这四种学习方式——一方面,还存在其他的LbT方式,例如通过想象学习;另一方面,这些学习方式均可细化,例如当提到通过解释进行学习时,目的论解释与机制性解释又有所差别。
事实上,由于学习过程与注意力、记忆等其他认知机制之间存在错综复杂的关系,因此很难对其进行根本的分类。相反,我们探讨的这四种学习过程,可以帮助我们理解LbT的普遍性(ubiquity)和长处,平行比较人类思维与人工智能。
▷学习的不同类型. 图源:[2]
(1)通过解释进行的学习
在一项经典研究中[3],研究人员发现“优秀”学生与“后进”学生在学习材料时表现出不同的策略。优秀学生更倾向于花更多时间向自己解释文本和示例。后续研究通过提示或指导,鼓励学生进行解释,结果显示解释确实能提高学习效果,尤其是在超出学习材料本身的问题上,效果更为明显。当学习过程中没有外界反馈时,解释性学习便成为了一种LbT。这种学习方式可以分为两类,纠正性学习(corrective learning)和生成性学习(generative learning):
纠正性学习中,学习者识别并改进现有表征中的缺陷。例如,“解释深度错觉( illusion of explanatory depth,IOED)”现象表明,人们常会高估自己对设备运作原理的理解,在尝试解释后,往往才能更清楚地认识到自己理解的局限性[4]。
生成性学习则指学习者通过解释从而构建新的表征。例如,在学习新类别时,在提示下进行解释的参与者,更有可能生成抽象表征并识别示例中的广泛模式。
类似的思路也在AI研究中得到应用,例如通过生成自我解释,AI系统从训练集中提取信息,从而实现泛化。最新研究还表明,深度强化学习系统在生成任务答案的同时,若能够生成针对答案的自然语言解释,其在关系推理和因果推理任务中的表现将优于没有进行解释预测的系统,甚至优于那些将解释作为输入的系统。这些系统并非仅依赖简单特征,而是能够从复杂数据中总结出可泛化的信息。

▷图源:GPT
(2)通过模拟进行学习
想象有三个齿轮水平排列,最左边的齿轮顺时针旋转,此时最右边的齿轮会向哪个方向转动?
大多数人会通过“心理模拟(mental simulation)”来解决这个问题:在脑海中构建齿轮运动的画面,观察每个齿轮的转动方向。纵观科学史,许多领域的思想实验亦是经典的心理模拟。例如,爱因斯坦通过模拟光子与火车的运动来探讨相对论,伽利略则通过模拟物体下落的过程来研究重力。这些心理模拟与思想实验,无需依赖外部新数据,便能带来深刻的见解。
和解释性学习类似,心理模拟可以是纠正性的,也可以是生成性的。
一个纠正性心理模拟例子是:在一项研究中,参与者同时进行两种思想实验——一种符合牛顿力学的直觉,另一种则诱发错误的动力论思维(如认为物体需要持续施力才能运动)。这些不同的思想实验使参与者产生了矛盾的直觉,有时依据牛顿力学做出正确判断,有时则被动力论的误导所影响。然而,实验结束后,参与者通过思想实验纠正了原有的错误直觉,不再支持那些与动力论相关的错误判断。
而生成性心理模拟的示例则见于因果推理中。当判断一个事件是否导致另一个事件时,人们通常会进行“反事实模拟”。例如,在一项实验中,展示了第一颗球撞击第二颗球,使其改变轨迹并到达目标。参与者通过反事实模拟,设想如果第一颗球没有撞击,第二颗球的轨迹会如何变化,从而判断因果关系。
类似的模拟过程也广泛应用于AI领域。例如,在深度强化学习中,“基于模型的训练方法”利用环境表征生成数据来训练策略,这与人类的心理模拟十分相似。某些AI算法通过“深度想象”或模拟多组决策序列,来近似求解最佳方案。在人类和AI中,模拟都能生成“数据”,为学习和推理提供重要输入。
▷图源:Corey Brickley
(3)通过类比推理和比较进行学习
在构建自然选择理论时,达尔文类比了人工选择与生物进化,由此推导出自然选择中的变异机制。这样的类比推理在科学研究中很常见,尤其当研究者对比较的对象双方有一定了解时,通过类比思维可以产生新的见解,支持“通过思考学习”。
通过类比进行的学习并不完全依赖自主思考,还结合了外部信息,因此学习结果既反映了研究者提供的信息内容,也反映了参与者的类比思维能力。然而,有些研究将类比思维的影响独立出来,所有参与者接收相同的类比信息,但只有部分被提示在解决新问题时运用这些信息。
例如,一项数学学习研究表明,被试被提醒进行样本比较的次数越多,他们越不易被题目表面的相似性误导,这展示了类比学习的纠正性作用。另一项实验要求被试找出两组机器人之间的相似性和差异,结果发现,只有那些积极进行比较的参与者更可能发现微妙的规则,展示了类比思维的生成性作用。
类比推理在人工智能领域也受到关注。与人类实验相似,大多数类比推理演示并非纯粹的LbT,更多地AI系统会被要求解决涉及源类比的类似问题。然而,最近的研究表明,不提供源类比的情况下,机器也能通过自身的思维或知识构建类比[4]。在数学问题、代码生成等任务中,最有效的提示是要求大语言模型(LLM)生成多个相关但多样化的示例,描述各个示例并解释其解决方案,然后再给出新问题的解决方案,这个过程可能融合了推理和解释。这样的类比提示的表现优于许多最先进的LLM性能基准,与人类在比较提示下的学习效果有一定相似性。
通过类比推理,不仅可以纠正错误,还能激发更深层次的思考,发现新的概念或规则,无论在人类学习还是人工智能中,都是重要的学习机制。

▷图源:NGS ART DEPT
(4)通过推理进行学习
即使是看似简单的推理过程,也需要正确的信息和逻辑处理。例如,我可能知道今天是星期三,也知道“如果今天是星期三,就不应该在某个校区停车”,但由于各种原因,我可能会忽略这一逻辑关系,而把车误停在了禁止停车的地方。这说明,即使逻辑成立,推理时仍需额外的注意和处理能力。
更复杂的推理,则需要更深入的思考。比如:
前提1:“每个人都爱曾经爱过别人的任何人”;
前提2:“我的邻居莎拉爱泰勒·斯威夫特”;
推论:“因此,唐纳德·特朗普爱卡马拉·哈里斯”。
在现实中,这样的推理结论可能难以接受,这表明有效的推理不仅需要逻辑推导,还需要反思和实际判断。
推理也能起到纠正作用[4]。一项研究让参与者评估推理问题回答的论证,他们并不知道这些论证来自于自己此前的回答,结果显示,三分之二的参与者能够正确否定自己之前做出的无效推理。这类纠正性的推理在认识错误直觉中发挥着重要作用。比如“认知反思测试(cognitive reflection test,CRT)”中的经典问题“球拍与球”:球拍和球的总价为1.10美元,球拍比球贵1美元。直觉答案是0.10美元,但正确答案是0.05美元。推理得出正确答案需要克服初步的直觉反应,进行更严谨的思考。
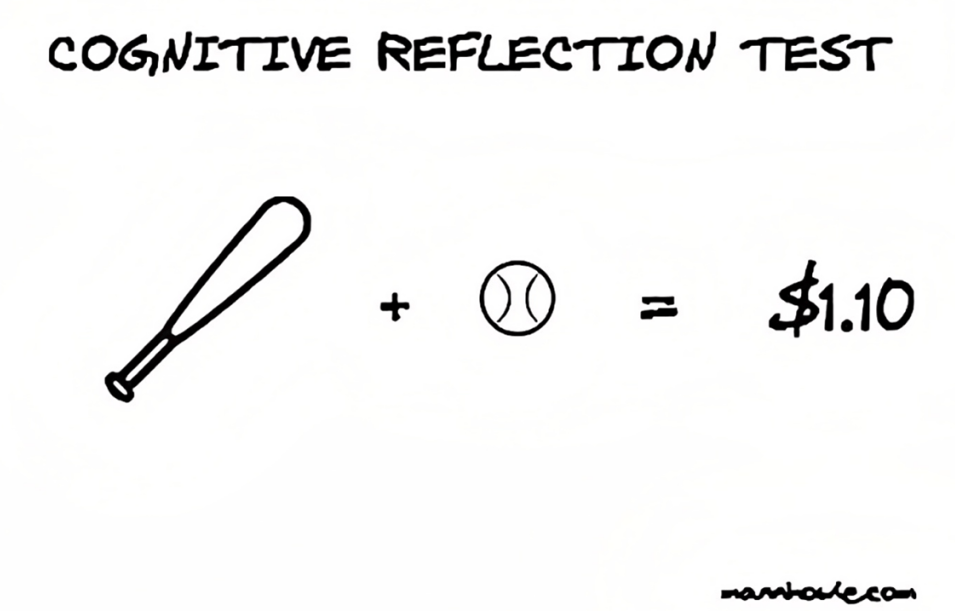
▷图源:mannhowie.com
在人工智能领域,传统符号架构的推理通常依赖明确的规则或概率计算。而深度学习系统(如大语言模型)的推理能力仍处于发展中。在解决复杂问题时,提示LLM进行逐步推理,以此克服直接提示下的错误倾向,被证明更为有效。这种推理方式的优势在应对高难度任务时尤为突出,这展现了AI在推理领域的潜力。
02 解开LbT的谜题
在前文中,我们探讨了自然脑与机器脑如何通过思考进行学习,尽管它们的运作机制不同,但都面临同样的问题——
为什么“思维”本身就能促进学习?
诗人兼剧作家海因里希·冯·克莱斯特曾论述过“通过说话来学习”的益处——通过向他人表达思考,我们能够在“推理的工坊”中理清和发展自己的想法。他还提出了解释LbT悖论的“思维即学习”思路:学习的并不是我们作为个体的自我,而是我们心智中的某种特定状态。换句话说,LbT中的“学习”并非创造全新的知识,而是让已有的知识变得可获取。思维之所以能够成为学习的源泉,是因为知识的基础早已存在于心智中,只是尚未被我们清晰意识到。
从认知的角度来看,“通过推理进行学习”的过程是学习者将两个前提结合,得出一个在逻辑上已经成立但未明确认识的结论。尽管结论已蕴含在前提中,唯有通过推理过程,将结论变得显而易见,才构成了学习。在这个过程中,推理不仅是机械地组合信息,还产生了一个全新表征,这一表征独立于前提而存在。
▷图源:Caleb Berciunas
将这一思路应用到“通过解释进行学习”时,情况变得复杂得多。因为解释过程中,学习者往往并不清楚什么是明确的“前提”,此时表征的“可及性”便显得尤为关键。不同类型的输入会影响表征的提取。例如,当我们处理“加法”时,输入的是阿拉伯数字还是罗马数字,会显著影响我们对输入特征的感知(如奇偶性),并且可以通过不同的算法(如解释、比较和模拟)来改变可及性条件,从而支持“表征提取(representational extraction)”,创造出具有新可及性条件的全新表征。
表征提取是指通过思考或推理,形成一个特定的认知结构,这个结构具有不同的“可及性”条件。一旦表征被提取出来,它就变成某种前提,继而限制了输出的范围。
在“通过解释进行学习”中,这一点尤为明显——当学习者展开解释时,倾向于选择“根原因(root causes)”较少的解释,也就是说,他们更愿意认为某些因果假设比其他假设更合理、更优越。这样的选择形成了一种隐性前提,限制了后续推理的空间。例如,当学习者对某一解释产生偏好时,这种偏好本身就构成了新的前提,进而影响接下来得出的结论。

▷通过推理和解释的思考的行动. 图源:[2]
理解“可及性”差异和表征提取的作用,能够帮助我们将推理学习的逻辑推广至其他学习形式,如解释、比较和模拟。每种形式中的认知过程,都可以看作是通过不断提取新的表征,建立新的推理前提,从而逐步推进学习的进程。但这无法解决另一个问题——
为什么要期望通过解释、模拟或其他LbT过程得出的结论能够产生新的“知识”,即真实的、符合事实的知识?
当然,LbT的输出不一定总是正确的。然而,由于这些过程可能受进化、经验或人工智能设计的影响,我们可以合理地假设,LbT至少部分反映了世界的结构,因此有可能产生相对可靠的结论[5]。即使输出不完全准确,它们仍能在引导思维和行动上发挥作用。例如,通过解释进行学习时,即使生成的解释有误,解释的过程本身可能改善后续的探究和判断,比如帮助学习者识别表征之间的冲突,或者以更抽象的方式表征某个领域。
理解了LbT的机制和潜在价值后,接下来的问题是——
为什么LbT是“必要的”?
我们可以通过计算机系统类比来解释。在人工系统中,内存和处理时间的限制决定了能进行多少前瞻性计算。LbT提供了一种按需生成新颖且有用表征的方法,而不是单纯依赖已有的学习结果。因此,可以假设,LbT在资源(如时间、计算能力)有限的智能体中尤为普遍[6],尤其是在面对未来环境和目标不确定性的情况下。
这些观察还预示了自然思维与人工思维在LbT作用上的差异。随着人工智能逐渐克服人类思维的资源限制,或者当它们处理的问题不涉及高不确定性时(比如在非常狭窄的领域操作),我们预期在这些条件下,人工智能与人类在LbT过程中的表现将会出现显著差异。
03 总结
"通过思考进行学习"(LbT)几乎无处不在:人类不仅通过观察学习,还通过解释、比较、模拟、推理等方式获取知识。近年来的研究表明,人工智能系统也能够以类似的方式进行学习。在这两类情境下,我们可以通过认识到表征的“可及性”条件会发生变化,来破解LbT的悖论。LbT使得学习者能够提取具有新可及条件的表征,并利用这些表征生成新的知识与能力。
从某种意义上来说,LbT揭示了认知的局限性。一个拥有无限资源且面对有限不确定性的系统,可以在观察的同时立即计算出其所有后果。然而,现实中,无论是自然智能还是人工智能,都面临资源的有限性和对未来判断、决策相关性的高度不确定性。在这种背景下,LbT提供了一种按需学习的机制,充分利用现有表征来应对代理当前所处的环境和目标。
尽管如此,关于LbT在自然智能和人工智能中的实现,还有许多未解之谜。我们尚不完全明白,这些过程如何具体地促进人类智能的发展,或者它们在何种情况下可能引导我们走向错误的方向。要揭示这些问题的答案,不仅需要深入的思考,更需要依赖跨学科的认知科学工具包的支持。
参考文献
[1] WEI J, WANG X, SCHUURMANS D, et al. Chain of Thought Prompting Elicits Reasoning in Large Language Models [J]. ArXiv, 2022, abs/2201.11903.
[2] Lombrozo, Tania. “Learning by thinking in natural and artificial minds.” Trends in cognitive sciences, S1364-6613(24)00191-8. 20 Aug. 2024, doi:10.1016/j.tics.2024.07.007
[3] CHI M T H, BASSOK M, LEWIS M W, et al. Self-Explanations: How Students Study and Use Examples in Learning to Solve Problems [J]. Cognitive Science, 1989, 13(2): 145-82.
[4] ROZENBLIT L, KEIL F. The misunderstood limits of folk science: an illusion of explanatory depth [J]. Cognitive Science, 2002, 26(5): 521-62.
[5] TESSER A. Self-Generated Attitude Change11Preparation of this chapter was partially supported by grants from the National Science Foundation (SOC 74-13925) and the National Institutes of Mental Health (1 F32 MH05802-01). Some of the work was completed while the author was a Visiting Fellow at Yale University. I am indebted to Robert Abelson and Claudia Cowan for reading and commenting on preliminary versions of this chapter [M]//BERKOWITZ L. Advances in Experimental Social Psychology. Academic Press. 1978: 289-338.
[6] BERKE M D, WALTER-TERRILL R, JARA-ETTINGER J, et al. Flexible Goals Require that Inflexible Perceptual Systems Produce Veridical Representations: Implications for Realism as Revealed by Evolutionary Simulations [J]. Cogn Sci, 2022, 46(10): e13195.
[7] GRIFFITHS T L. Understanding Human Intelligence through Human Limitations [J]. Trends in Cognitive Sciences, 2020, 24(11): 873-83.