近日,一股复现DeepSeek的热潮在全球范围内迅速兴起,引发科技界的广泛关注。UC伯克利、香港科技大学以及HuggingFace等知名机构纷纷宣布成功复现了这一模型,标志着人工智能领域或许即将迈入一个新的发展阶段。
DeepSeek以其独特的强化学习路径而著称,无需监督微调,仅凭强化学习便能让基础语言模型展现出强大的自我验证和搜索能力。这一特性使得DeepSeek成为众多研究者争相复现的对象。据透露,复现DeepSeek的成本极低,仅需约30美元便能亲眼见证其“啊哈时刻”——模型在强化学习过程中突然展现出强大推理能力的瞬间。

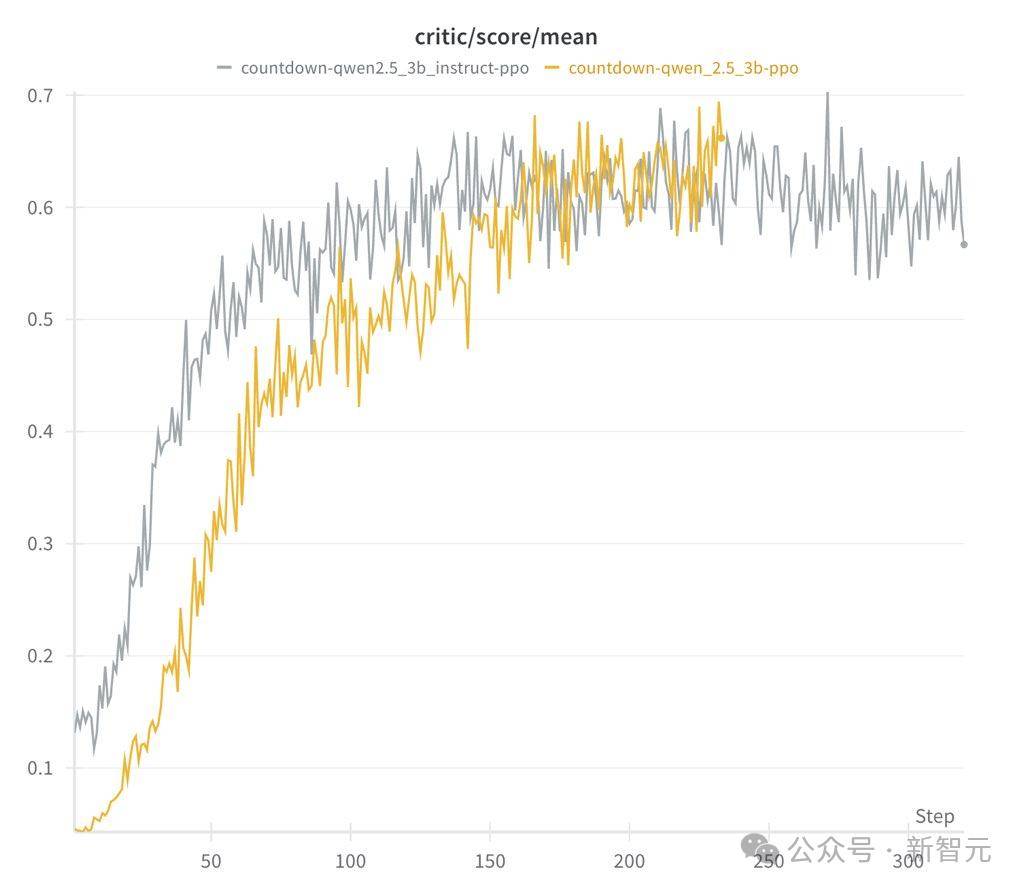
UC伯克利的博士生潘家怡及其团队在CountDown游戏中复现了DeepSeek的R1-Zero版本,并取得了令人瞩目的成果。他们通过强化学习,让30亿参数的基础语言模型逐步进化出自我纠正和搜索的策略,成功解决了游戏中的复杂问题。这一成果不仅验证了DeepSeek的有效性,也进一步证明了强化学习在推动人工智能发展方面的巨大潜力。
与此同时,香港科技大学助理教授何俊贤的团队也在70亿参数的模型上复刻出了DeepSeek-R1-Zero和DeepSeek-R1的训练过程。他们仅使用了8000个样本,便让模型在复杂的数学推理上取得了强劲的表现。这一成果不仅超越了基础模型的性能,还与使用大量数据和复杂组件的其他模型相媲美。

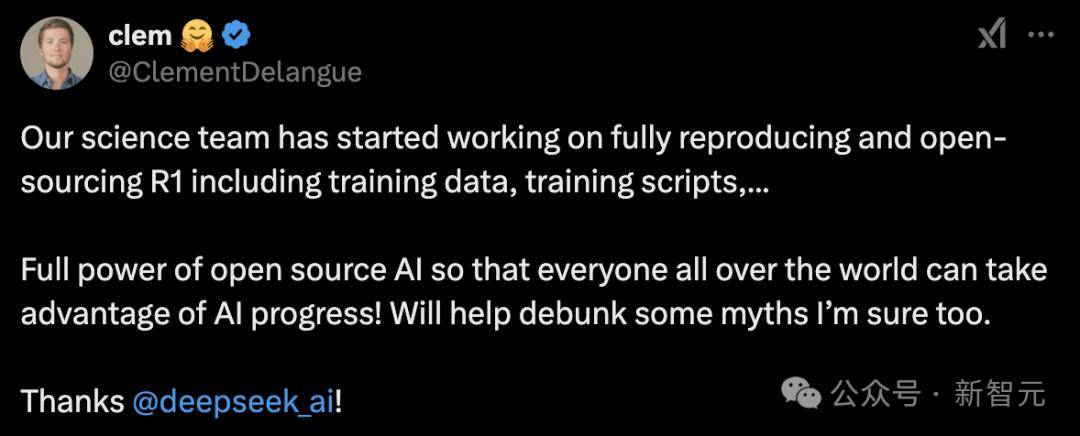
全球最大的开源平台HuggingFace也宣布将复刻DeepSeek的R1所有pipeline。他们表示,复刻完成后,所有的训练数据、训练脚本等都将全部开源。这一举措无疑将进一步推动DeepSeek技术的普及和发展。
DeepSeek的成功复现,不仅让科技大厂们感受到了前所未有的压力,也让全球人工智能的中心转移问题再次成为热议话题。有观点认为,DeepSeek的出现标志着美国AI霸权的动摇,全球AI大模型的竞争将不再局限于算力战,而是更加注重算法和技术的创新。
DeepSeek的复现也引发了对人工智能未来发展的广泛讨论。有人认为,随着技术的不断进步和成本的降低,超强性能的模型将不再独属于算力巨头,而是属于每个人。这一观点无疑为人工智能的普及和发展带来了更多的可能性和希望。