在科技界的聚光灯下,英伟达创始人黄仁勋于GTC 2025大会上再度亮相,身着标志性的皮衣,风采不减当年。尽管近期英伟达股价遭遇重创,跌至十年谷底,但黄仁勋对自家最新GPU的信心并未动摇。
回想起今年2月,AI领域迎来了一场震撼——DeepSeek横空出世。这个由中国团队打造的产品,仅凭少量低端GPU(以A100为主),通过蒸馏现有超大模型,便实现了高端GPU(如H100)级别的性能。这一突破,无疑对“Scaling Law”(规模定律)的传统观念造成了巨大冲击,该定律曾认为模型参数量、数据集和训练成本越多越好。过去,谷歌、meta、微软等科技巨头纷纷斥巨资采购H100芯片,试图以算力决胜未来。然而,DeepSeek的出现似乎让这一切变得不再必要。
一时间,关于DeepSeek或将终结英伟达时代的言论甚嚣尘上,尤其在海外社交媒体上,这一观点被迅速传播和发酵。有网友直言,英伟达的一切即将开始瓦解。在此背景下,英伟达的股价频繁遭遇重创,单日跌幅13%、17%成为常态。
然而,也有另一种声音认为,从长远来看,DeepSeek的成功反而可能对英伟达构成利好。虽然DeepSeek揭示了通过蒸馏超大模型来训练高性能大模型的方法,降低了对H100等高性能芯片的需求,但并未完全摆脱对计算卡的依赖。A100计算卡,同样是英伟达的产品。随着玩家门槛的降低,更多玩家涌入市场,算力需求总量仍将上升。要蒸馏现有超大模型,首先需要有高性能的超大模型存在,这仍然需要H100等计算卡集群进行训练。因此,两种观点各有千秋。
在万众瞩目的GTC 2025大会上,黄仁勋终于亲自回应了DeepSeek带来的冲击。他首先高度评价了DeepSeek R1模型,称其为“卓越的创新”和“世界级的开源推理模型”,并表示不理解为何人们会将DeepSeek视为英伟达的末日。
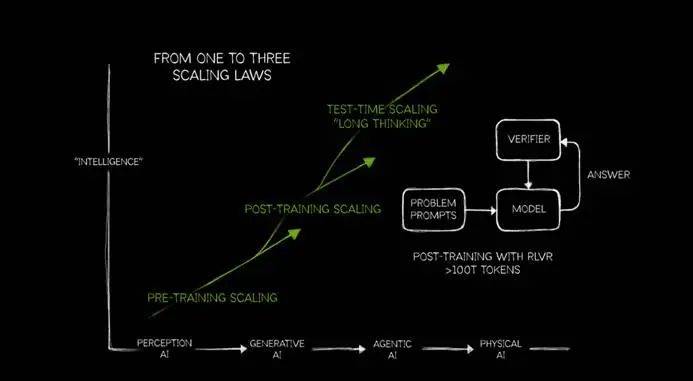
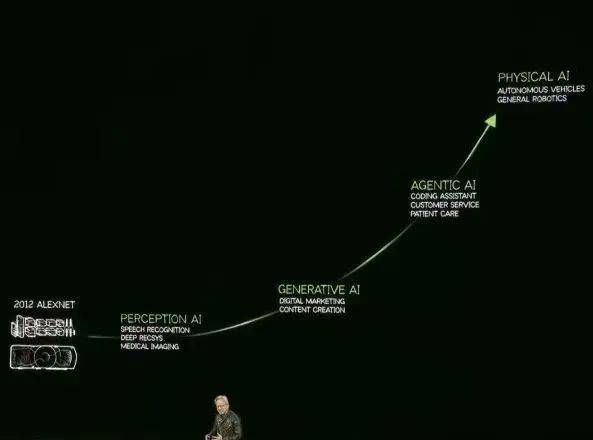
针对Scaling Law是否撞墙的讨论,黄仁勋给出了自己的见解。他对Scaling Law进行了迭代更新,将其细分为PRE-TRAINING SCALING、POST-TRAINING SCALING和TEST-TIME SCALING三个部分。他认为,随着AI进入不同阶段,对Scaling的需求不断提高。目前,AI正处于代理人工智能阶段,由于推理模型和AI代理的爆发,对算力的需求更加迫切。
黄仁勋强调,token是背后的关键。以推理模型为例,模型进行推理时,token的消耗急剧增加。他指出,不仅需要提升token的吞吐量十倍,还需要过去十倍的算力来提升token的输出速度,最终需要的算力是之前的100倍。相比传统的生成式模型,如ChatGPT,推理模型如DeepSeek R1会有一连串的推理过程,消耗更多的算力和token。因此,推理模型的推理过程需要展示出来,不仅因为用户可以从推理过程中介入修正答案,还因为推理过程消耗了token,是真金白银的付出。
黄仁勋还通过对比传统模型Llama 3.3 70B与DeepSeek R1 671B在处理复杂问题时的token消耗,进一步证明了其观点。Llama 3.3 70B消耗了400多个token但结果不可用,而DeepSeek R1虽然结果完美,但消耗了高达8559个token。
事实上,在高token消耗时代,英伟达的GPU销量反而更加迅猛。OpenAI、马斯克旗下的xAI、meta以及国内的阿里、小米、腾讯等公司纷纷加大算力投入,背后的显卡供应商主要来自英伟达。在个人本地部署领域,尽管DeepSeek R1降低了训练算力需求,但推理模型对算力的要求依然不低。以RTX 4080为例,在部署DeepSeek R1蒸馏模型时,推理速度较慢,需要更高配置的硬件才能提升效率。
然而,黄仁勋在GTC 2025大会上频繁提及token,甚至被媒体调侃为“贩卖token焦虑”。自新年以来,英伟达市值下跌近30%,黄仁勋在发布会上的表现更像是一个絮絮叨叨的金牌销售,而非技术大拿或全球最牛公司的CEO。尽管他的逻辑看似合理,但如此频繁地重复,让人不禁觉得英伟达有些歇斯底里。
英伟达现在缺乏的并非技术和产品,而是对消费者的诚意。在GPU领域,英伟达一骑绝尘,但真正的挑战在于如何赢得消费者的信任和忠诚。尽管黄仁勋试图通过贩卖token焦虑来重塑市场对英伟达的信心,但真正的考验在于英伟达能否拿出更多令人信服的产品来回应市场的期待。